

LLM's Accuracy - Self Refinement

Started out this path from working with MIPS assembly at around 12 years old, and for some reason ended working mostly on fullstack.
Self-refinement is a technique where the model evaluates and refines its own output. Normally, when using an LLM, you provide a prompt and the model generates a completion. With self-refinement, you can instruct the model to review the content it has generated, score it, and refine the output. This process can be repeated multiple times, allowing the model to iteratively improve its own output.
For instance, if the model is asked to write a tweet, it can then be prompted to make the tweet more engaging, rate its quality, and refine it accordingly.
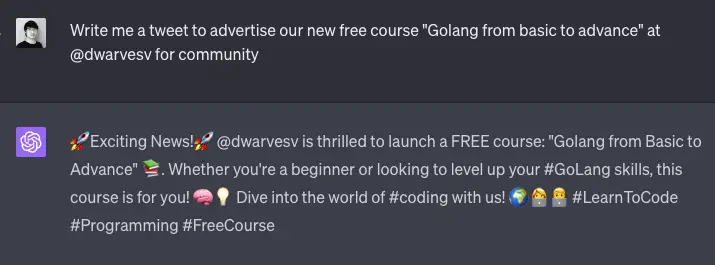
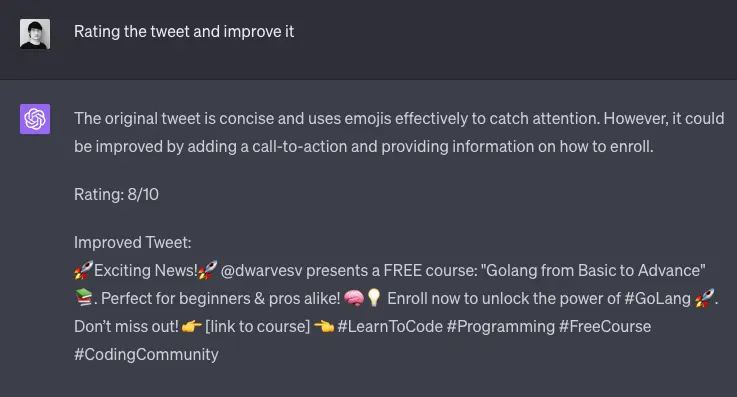
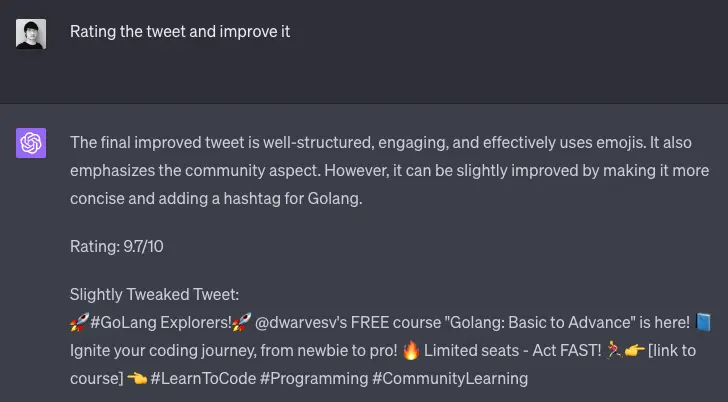
Notably, this technique does not require supervised data or [[Reinforcement Learning | reinforcement learning]]. The model's ability to self-evaluate and refine its output is inherent, making this a powerful and efficient method for improving LLM's accuracy.
Key Points:
- Self-refinement involves the model reviewing, scoring, and refining its own output.
- The technique has been effective, especially for models like GPT-4.
- It outperforms baselines in many use cases without the need for supervised data or reinforcement learning.



