



Exploring Machine Learning Approaches for Fine-tuning LLaMA models


At Dwarves, we've been increasingly exposed to more state-of-the-art news coming from AI than ever before, of course, related to Large Language Models (LLM). We've had a taste of what AI has to offer with Stable Diffusion and more commercial apps, and have been eager to learn and hone our skillsets in applying these new AI breakthroughs in our everyday lives and our apps.
Introduction
If 2021 was the year of blockchain, it's probably safe to say that 2023 is the year of generative AI. The pace and progress of AI, and by extension AGI, is becoming very hard to keep up. Apps using OpenAI ChatGPT are just saturating the market, but there are already fears that ChatGPT plugins could take over a good majority of their use cases.
There has also been an increasing amount of interest in custom LLaMA models, almost a similar trend to what we saw with Stable Diffusion against DALL-E. The landscape for LLMs has been progressing at a neck-breaking pace, with the mean time for outdated AI news becoming closer to within a single day.
We're at a point where everything is moving fast and no one is yet an expert in the field of AI. We felt that we would get left behind if we at least didn't take a look at the technical side of AI, which eventually motivated our research in LLMs.
Prior Research
For AI, a lot of us at Dwarves use available tools to help us to do extensive learning, get over writer's block, experiment, and generally make our lives a little bit easier. A handful of us, including myself, have dabbled a bit in Stable Diffusion, mostly to create fun pictures, but also to help us get an idea of the current landscape of generative art.
For research on LLMs, we've investigated vector databases and how to apply a basic form of indexing on them for use with OpenAI. You can check out our basic example at https://df-doc-search.vercel.app/ and ask it some questions about our company, although don't expect too much 😶.
Likewise, we've created a few Jupyter notebooks working on Langchain and what strategies and utilities we use from it to generate more directed results. You can view some of what we've worked on and noted here:
Workaround with OpenAI's token limit with Langchain - The Dwarves Brainery
Working with langchain document loaders - The Dwarves Brainery
https://colab.research.google.com/drive/1FMbBYPLz01lLma4jK36-fABjQC2vhyRJ?usp=sharing
https://github.com/dudaka/automating-pdf-interaction-with-langchain-and-chatgpt
Problem
Using OpenAI is great, but we will eventually find ourselves needing to use more private LLM models. Unlike Microsoft's Azure, a lot of companies don't have the opportunity or financial resources to make deals with OpenAI for data security and fine-tuning privacy for their foundational AIs. Along with efforts on engineering prompts with Langchain, we want to eventually fine-tune our own LLMs to suit more specialized needs to then pipeline them together for more complex use cases in the future.
While we want to fine-tune more private (and of course personal) LLMs, we want to do it in a way that doesn't reinvent the wheel and break the bank. We don't want to spend thousands of dollars just to recreate something that ChatGPT already does. There already has been huge progress in the open-source community with Dolly 2.0 and StableLM and we're not going to win the race on base models even if we joined.
Adapter fine-tuning with PEFT LoRA
One novel approach to enhancing the performance of LLMs involves the fine-tuning of LLaMA models using a technique called PEFT LoRA (Parameter-Efficient Fine-Tuning with Layer Rotation Attention). PEFT LoRA offers a cost-effective and efficient way to adapt models with very little data, given a strong instruction model. It is very similar to Dreambooth LoRA for Stable Diffusion, but with much less hassle.
How does it work?
PEFT LoRA works on top of pre-trained language models by adding LoRA weights to the feed-forward layer of the transformer. It does this in a way without needing to fine-tune all of the model's parameters. This is particularly great if the majority of the AI workload is in vector indexing and we just want a chatbot specialized for a particular dialogue path without sounding too stupid.
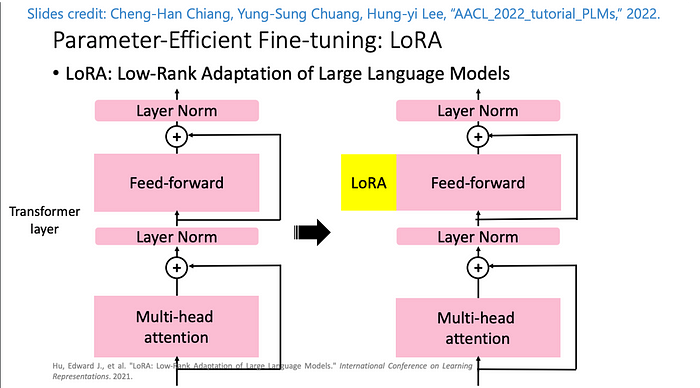
The trained weights from PEFT LoRA are significantly much smaller (within a few MBs depending on your data) and don't require as much CPU/GPU power to fine-tune existing frozen models.
Proof of Concept
For the moment, we just want to get our first foot out the door, since not many of us have experience in creating machine learning pipelines. The proof of concept here will be to:
Train with base model to output PEFT LoRA adapters
Use the PEFT LoRA adapters with the base model at runtime and ask it questions
Save the adapter files for later use
Merge the PEFT LoRA adapters to the frozen model and save those files for later use
As such, the dataset we will use here will be sparse and probably won't do much to change the pattern behavior of the model. Things like feature engineering or labeling data appropriate for instruction or prompt tuning we can hold off for later.
Preparing data for instruct-tuning
We will do some basic instruct-tuning using wxjiao/alpaca-7b as the base model. We set up our prompts for training, similar to https://github.com/gururise/AlpacaDataCleaned, which will have an instruction query, an input for contextual reference, and an expected output dialogue:
{
"instruction": "What is Dwarves Foundation's community all hands?",
"input": "",
"output": "An event hosted every end of the month on Friday, at a Discord stage where we talk about our company progress along with notable news and wins across the month. After every community all hands, we host a company dinner where everyone working at Dwarves are invited."
}
Loading the dataset
We then load our very small sample dataset to a data map, that will have our list of data points tokenized and formatted to our generate_prompt function.
from datasets import load_dataset
data = load_dataset("json",
data_files="./dwarves-dataset/dwarves_sample_dataset.json")
def generate_prompt(data_point):
# taken from https://github.com/tloen/alpaca-lora
if data_point["instruction"]:
return f"""Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
{data_point["instruction"]}
### Input:
{data_point["input"]}
### Response:
{data_point["output"]}"""
else:
return f"""Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{data_point["instruction"]}
### Response:
{data_point["output"]}"""
data = data.map(lambda data_point: {"prompt": tokenizer(generate_prompt(data_point))})
Fine-tuning the model
Training the model is surprisingly simple and transparent. Most of the work for the fine-tuning is really in how we configure it, and of course how we label our data.
We first need to set our config for the LoraConfig class. We prepare them as environment variables to help manage them easier. There are also some environment variables set specifically to our Google Colab resources, which we used to run our fine-tuning.
# Settings for A100 - For 3090
MICRO_BATCH_SIZE = 4 # change to 4 for 3090
BATCH_SIZE = 128
GRADIENT_ACCUMULATION_STEPS = BATCH_SIZE // MICRO_BATCH_SIZE
EPOCHS = 2 # paper uses 3
LEARNING_RATE = 2e-5
CUTOFF_LEN = 256
LORA_R = 4
LORA_ALPHA = 16
LORA_DROPOUT = 0.05
We then prepare our model for training and apply our environment variables to our LoraConfig and bind it to our model:
model = prepare_model_for_int8_training(model, use_gradient_checkpointing=True)
config = LoraConfig(
r=LORA_R,
lora_alpha=LORA_ALPHA,
lora_dropout=LORA_DROPOUT,
bias="none",
task_type="CAUSAL_LM",
)
model = get_peft_model(model, config)
tokenizer.pad_token_id = 0
data = load_dataset("json", data_files="./dwarves-dataset/dwarves_sample_dataset.json")
data = data.shuffle().map(
lambda data_point: tokenizer(
generate_prompt(data_point),
truncation=True,
max_length=CUTOFF_LEN,
padding="max_length",
)
)
With the updated model, we then use it to set up our model trainer with the rest of the training variables we set earlier.
trainer = transformers.Trainer(
model=model,
train_dataset=data["train"],
args=transformers.TrainingArguments(
per_device_train_batch_size=MICRO_BATCH_SIZE,
gradient_accumulation_steps=GRADIENT_ACCUMULATION_STEPS,
warmup_steps=100,
num_train_epochs=EPOCHS,
learning_rate=LEARNING_RATE,
fp16=True,
logging_steps=1,
output_dir="lora-alpaca",
save_total_limit=3,
),
data_collator=transformers.DataCollatorForLanguageModeling(tokenizer, mlm=False),
)
model.config.use_cache = False
All that is left to do is run the trainer to train our model. Thankfully that method is a simple one-liner. The trainer will then output how many steps it has progressed through and output what the training loss is for each step.
trainer.train(resume_from_checkpoint=False)
Then if we want to save the file to our disk, we can use the save_pretrained method on our model to save it to a named folder.
model.save_pretrained("alpaca-lora-dwarves")
Talking to the model
We will use Dolly 2.0's instruction pipeline through InstructionTextGenerationPipeline to help us communicate and produce responses with the model:
generate_text = InstructionTextGenerationPipeline(model=model, tokenizer=tokenizer)
generate_text("What is the cold start problem in serverless architecture?")
# The cold start problem in serverless architecture is the phenomenon of a serverless function being triggered multiple times, which can significantly increase its execution time and costs. This is because each time the function is triggered, the entire code has to be executed, even if the previous execution didn't finish. To mitigate this, serverless functions can be designed to leverage environment variables, which allow certain variables to be set and shared between executions of the function.</s>
Saving the models to HuggingFace
On Google Colab or in Jupyter notebooks, we can directly login to HuggingFace with the use of an API token:
from huggingface_hub import notebook_login
notebook_login()
Then we can push our PEFT LoRA adapter files to a directed repository like so (monotykamary/alpaca-7b-lora-dwarves-poc):
model.push_to_hub("monotykamary/alpaca-7b-lora-dwarves-poc", use_auth_token=True)
In case we want to merge the adapter and base model to create a new model, we can use the merge_and_unload method and save it to our disk:
model = model.merge_and_unload()
model.save_pretrained("monotykamary/alpaca-7b-lora-merged-dwarves-poc")
If you want to then push that model to HuggingFace, since we've transformed our model, the function to push will be the same as above, but we'll just direct it to a different repository (monotykamary/alpaca-7b-lora-merged-dwarves-poc):
model.push_to_hub("monotykamary/alpaca-7b-lora-merged-dwarves-poc", use_auth_token=True)
Full Google Colab Example + HuggingFace
All of our examples, findings, and work are available on our Google Colab. You can view it there to get a full picture of our training pipeline.
You can also view our dataset and our output models on HuggingFace:
Further work
Our next step will likely be experimenting with different tuning methods and with much larger datasets to help our models better output certain dialogue patterns. We are interested in testing out a few ideas on applying Langchain with our fine-tuned models as well.
In addition, we also aim to make our pipeline more cloud agnostic by using SkyPilot. Google Colab and other tools have their own hardware limitations, not to mention high overhead costs for hosting portable Jupyter notebooks. Tools like SkyPilot is the novel equivalent of an easier-to-use Terraform for AI workloads. Vicuna also used SkyPilot to fine-tune their models, so we're excited to try it out.
Conclusion
In conclusion, after looking through a ton of resources, we were able to walk our first baby steps into the world of LLMs. Fine-tuning with PEFT LoRA has been a very insightful experience and has kind of opened our eyes to the fact of how low the barrier to entry AI has gotten. There's still of course a bit of nuance and "maneuvering" left to do with these models before they are app-ready, but we're looking forward to how we can apply these in the future.
Contributing
At Dwarves, we encourage our people to read, write, share what we learn with others, and contributing to the Brainery is an important part of our learning culture. For visitors, you are welcome to read them, contribute to them, and suggest additions. We maintain a monthly pool of $1500 to reward contributors who support our journey of lifelong growth in knowledge and network.
Love what we are doing?
Check out our products
Hire us to build your software
Join us, we are also hiring
Visit our Discord Learning Site
Visit our GitHub