





I had my fair share of interviews. Most of them are "traditional" QnA sessions, and unpaid take-home projects, and coding assessments. Dwarves's paid project is different and left a good impression on me.
The Beginning
At the time, I had been looking for a new job for a while, and somehow found Dwarves, which is a rare functional programming (Elixir) shop in Vietnam. Skimming the site and what people wrote, I found the organization fascinating: they value learning and craftsmanship. Getting intrigued by what I had discovered, I joined Dwarves's Discord, and sent a mail to apply, only to realize that I can ask people about open roles directly on Discord. I opened a ticket as instructed and got invited to a private channel to get to know the team. An online call (or kind of a screening round) was set up on the day after. A bounty (ticket of a task/paid project) was assigned to me a week later.
Working on The Bounty
If I were to pick a fancy name for what I had done, it would be: Discord Engagement Analytics. The project's end goal is to know Discord members' engagement with the server's channels or categories. Having screen time data (how much time are people spending on a particular channel, etc.) would be the perfect answer. However, all we have are messages and reactions from Discord, so we only can count the numbers (how many messages did a person sent to a channel, etc.), and use them to answer our questions imperfectly.
My leader/main helper for the project was Tom X Nguyen , who gave me a lot of useful suggestions. I occasionally get technical help from Nam and Huy, too.
In the first few days, I spent a bit of time to design the architecture and to get myself familiar with the codebases. Tom and I agreed that there would be two versions: AOT (stands for "ahead of time"; simpler; only allows current state queries) and JIT (stands for "just in time"; more complex; allow history state queries).
Design decisions
The simplest way to explain AOT and JIT's differences is to compare the data. Let us look at AOT's simplified table design:
discord_user_idchannel_idmessage_countreaction_count
The logic is that whenever we "catch" a new message, we increase message_count. This approach's advantages are its simplicity and low memory requirement. The disadvantage is that we only have the current state (how many messages have been since the beginning of time), and are unable to know the history state (how many messages were sent yesterday).
JIT's simplified table design looks like this:
message_iddiscord_user_idchannel_iddate_sent
The logic is that whenever we "catch" a new message, we create a new record like that. The advantage of this approach is that we will be able to the query history state, and the disadvantage is that the data can potentially be huge, and we might need complex data processing and storage solutions.
From the design stage, Tom and I agreed that I would try to complete the AOT version in 2 weeks. I finished the AOT version in around 10 day-ish. My demonstration is to send a message in the private Discord server, and to see message_count increases by one. In the few days left, I worked a bit on the JIT version while waiting for the final assessment to come.
Technical Implementation
Fortress API
On the Fortress API, one core function we use to get messages through a pull-based/polling design is through our GetMessagesAfterCursor function. Very similar to how we use block range in smart contract event fetching as a cursor to filter out the blockchain, we use a similar pull-based method for getting messages from Discord:
func (d *discordClient) GetMessagesAfterCursor(
channelID string,
cursorMessageID string,
lastMessageID string,
) ([]*discordgo.Message, error) {
cursorMessageIDUint, err := strconv.ParseUint(cursorMessageID, 10, 64)
if err != nil {
return nil, err
}
lastMessageIDUint, err := strconv.ParseUint(lastMessageID, 10, 64)
if err != nil {
return nil, err
}
allMessages := make([]*discordgo.Message, 0)
for cursorMessageIDUint < lastMessageIDUint {
messages, err := d.session.ChannelMessages(
channelID,
100, // 100 is the maximal number allowed
"",
cursorMessageID,
"",
)
if err != nil {
return nil, err
}
// reversal is needed since messages are sorted by newest first
for i, j := 0, len(messages)-1; i < j; i, j = i+1, j-1 {
messages[i], messages[j] = messages[j], messages[i]
}
allMessages = append(allMessages, messages...)
newestMessage := messages[len(messages)-1]
cursorMessageID = newestMessage.ID
cursorMessageIDUint, err = strconv.ParseUint(cursorMessageID, 10, 64)
if err != nil {
return nil, err
}
// a pause is needed to avoid Discord's rate limiting
time.Sleep(500 * time.Millisecond)
}
return allMessages, nil
}
The reasoning for this method was to avoid the case of losing messages as a push-based method would introduce lossy messages. The pull-based method would help use Discord as a backpressure to avoid losing messages when aggregating them to our database.
Fortress Discord
I noticed soon that there were some limitations to Discord's API on reactions. This meant the normal way to pull data from Discord for, specifically, reactions would be much more challenging. As an alternative approach, I implemented a push-based design for reactions to aggregate their numbers. This will be lossy in design, but it is our best alternative.
On the Fortress Discord repository, two main functions that help update our database associatively are onReactionCreate and onReactionRemove. These functions help simplify aggregating reactions when we have any events pushed from Discord.
func (d *Discord) onReactionCreate(s *discordgo.Session, m *discordgo.MessageReactionAdd) {
channel, err := s.Channel(m.ChannelID)
if err != nil {
l := d.L.AddField("channelID", m.ChannelID)
l.Error(err, "unable to get channel")
return
}
record := &model.EngagementsRollupRecord{
DiscordUserID: m.UserID,
LastMessageID: m.MessageID,
ChannelID: channel.ID,
CategoryID: channel.ParentID,
MessageCount: 0,
ReactionCount: 1,
}
l := d.L.AddField("record", record)
err = d.Command.S.Engagement().UpsertRollup(record)
if err != nil {
l.Error(err, "unable to upsert record")
return
}
l.Info("increased reaction count")
}
func (d *Discord) onReactionRemove(s *discordgo.Session, m *discordgo.MessageReactionRemove) {
channel, err := s.Channel(m.ChannelID)
if err != nil {
l := d.L.AddField("channelID", m.ChannelID)
l.Error(err, "unable to get channel")
return
}
record := &model.EngagementsRollupRecord{
DiscordUserID: m.UserID,
LastMessageID: m.MessageID,
ChannelID: channel.ID,
CategoryID: channel.ParentID,
MessageCount: 0,
ReactionCount: -1,
}
l := d.L.AddField("record", record)
err = d.Command.S.Engagement().UpsertRollup(record)
if err != nil {
l.Error(err, "unable to upsert record")
return
}
l.Info("decreased reaction count")
}
Demo
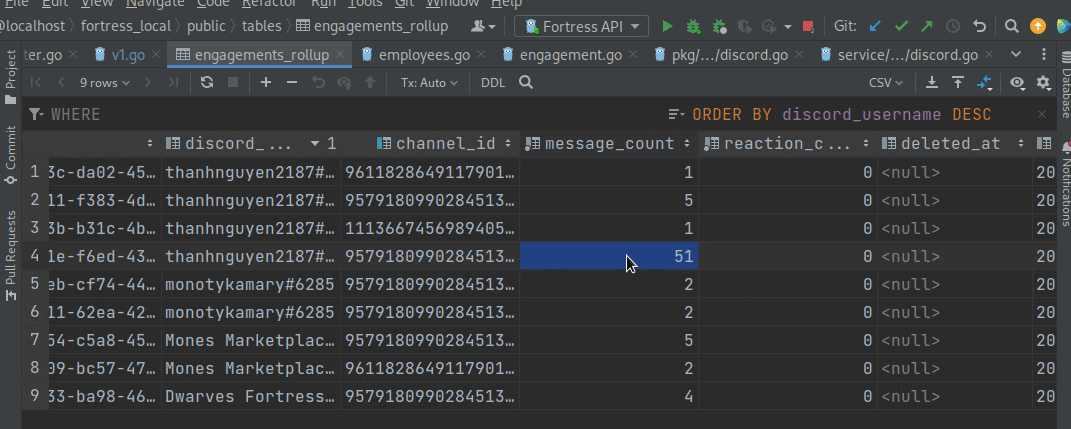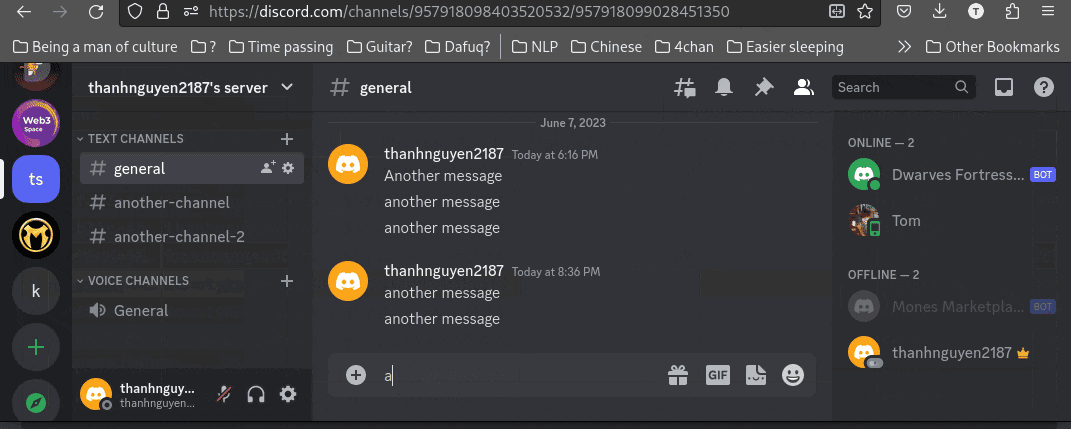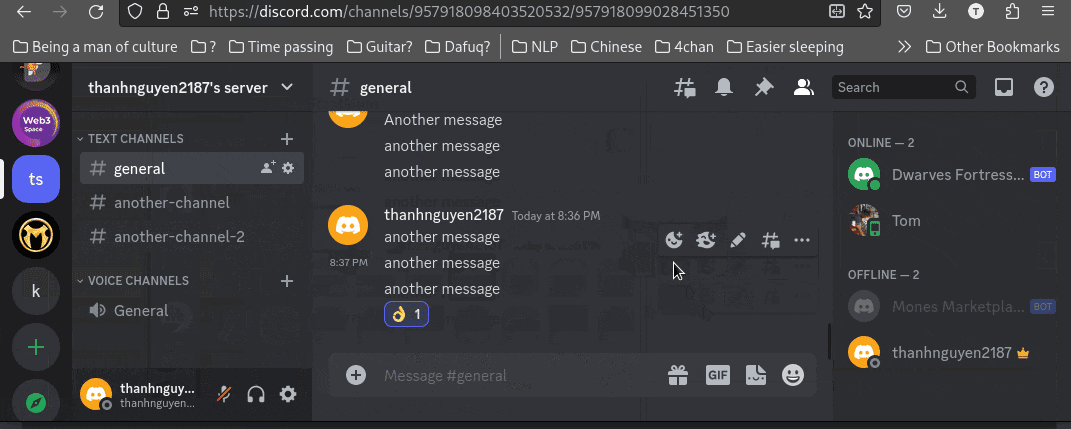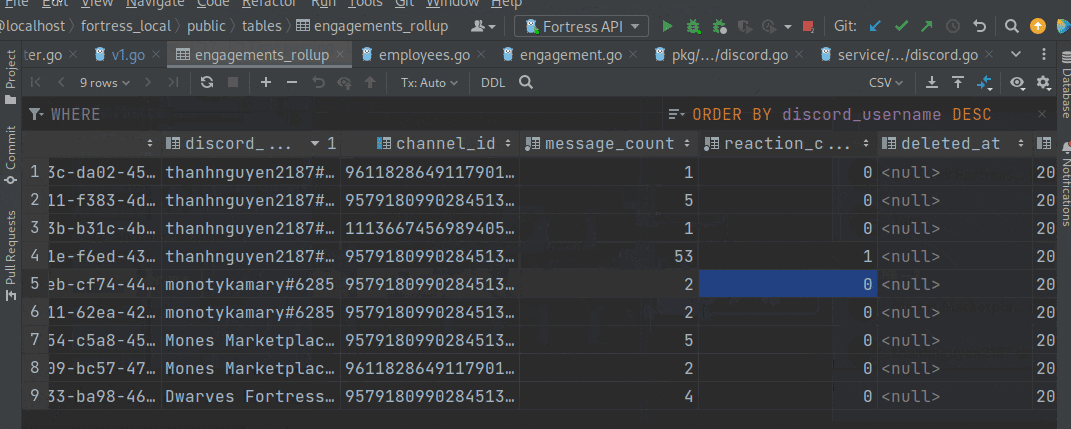
(you can see here that message_count increased after I sent a new message; the same went for reaction_count when I sent reactions)
Overall, the project went well without any major issues. However, I got a bit unlucky at my company-wide demonstration: sharing my screen on Discord did not work, and the host had to skip my section.
Conclusion
I learned a lot from this project: working with Discord API and understanding its limitation is one; new data engineering technical jargon to explain backend problems and solutions is another.
I heard about paid projects as an interviewing method before, but doing it with Dwarves is my first real experience with the method, and I feel fairly positive after all. The benefits are clear: the interviewer is going to have a clear understanding and a full evaluation of the interviewee, and the interviewee can also experience first-hand how is it working at the company. The drawback of time consumption for both sides can also be easily seen. Unable to be used at scale for manpower problems is another drawback that I find.
In the end, I enjoy my interviewing experience with Dwarves, and feel that they live up to their value of craftsmanship.
Contributing
At Dwarves, we encourage our people to read, write, share what we learn with others, and contributing to the Brainery is an important part of our learning culture. For visitors, you are welcome to read them, contribute to them, and suggest additions. We maintain a monthly pool of $1500 to reward contributors who support our journey of lifelong growth in knowledge and network.
Love what we are doing?
Check out our products
Hire us to build your software
Join us, we are also hiring
Visit our Discord Learning Site
Visit our GitHub